
Flow Matching#
In this notebook, we show how OTT can be used to estimate a time-dependent velocity field that can flow from a source to a target distribution following the flow matching approach (e.g. [Albergo et al., n.d., Lipman et al., 2022]). We explore three different approaches to couple source to target points, either the independent coupling that is the standard choice in flow matching, batch OT couplings (using the Sinkhorn algorithm) or through a solution to the semidiscrete problem (see [Mousavi-Hosseini et al., 2025, Pooladian et al., 2023, Tong et al., 2023, Zhang et al., 2025]).
# Basic imports
from collections.abc import Iterable
from typing import Callable, Dict, Literal, Optional, Tuple
from tqdm.auto import trange
import jax
import jax.numpy as jnp
import jax.random as jr
import numpy as np
import optax
from flax import nnx
import matplotlib.animation as mpa
import matplotlib.pyplot as plt
from IPython import display
# OTT geometries
from ott.geometry import costs
from ott.geometry import semidiscrete_pointcloud
from ott.geometry import semidiscrete_pointcloud as sdpc
# Semidiscrete couplings
from ott.math import velocity_from_brenier_potential
# Flow matching backbone
from ott.neural.data import ot_dataloader
from ott.neural.methods import flow_matching as fm
from ott.neural.networks.velocity_field import mlp
from ott.problems.linear import semidiscrete_linear_problem as sdlp
from ott.solvers.linear import semidiscrete
# Plotting
from ott.tools import plot
def to_video(ani: mpa.FuncAnimation) -> None:
display.display(display.HTML(ani.to_html5_video()))
Define synthetic task through ground-truth Brenier potential#
We pick a convex function \(\varphi\) to define a Monge map \(\nabla\varphi\) that is optimal w.r.t. the squared-Euclidean distance, per the Brenier theorem. Namely, we can pick a starting measure \(\mu\), and define \(\nu:= \nabla \varphi\#\mu\) and can guarantee that \(\nabla\varphi\) is the optimal map linking \(\mu\) to \(\nu\), whatever the measure \(\mu\).
# Define ground-truth potential phi
A = jnp.array([[-0.8, 0.4], [-0.1, -0.5]]) # linear transform
B = jnp.array([[0.5, 0], [0, 0.5]]) # positive definite matrix.
assert jnp.linalg.det(B) > 0.0, jnp.linalg.det(B)
@jax.jit
def phi(x: jnp.ndarray) -> jnp.ndarray:
"""Real-valued convex potential function."""
return (
2 * jnp.sum(jnp.abs(A @ x) ** 1.7)
+ jnp.sum(jnp.exp(B @ (x - 15)))
+ jnp.sum(jnp.abs(x - 1))
+ jnp.sum(jnp.abs(x - 2))
+ jnp.sum(jnp.abs(x - 7))
)
transport_fn = jax.jit(jax.vmap(jax.grad(phi)))
velocity_brenier = jax.jit(velocity_from_brenier_potential(phi))
We can plot the contours of that potential.
x = np.arange(-4, 8.0, 0.2)
y = np.arange(-4, 8.0, 0.2)
X, Y = np.meshgrid(x, y)
Z = jnp.array([jnp.array([xx, yy]) for xx, yy in zip(np.ravel(X), np.ravel(Y))])
Z = jax.vmap(phi)(Z).reshape(X.shape)
fig, ax = plt.subplots()
cont = ax.contourf(X, Y, Z.reshape(X.shape), levels=15)
fig.colorbar(cont)
ax.set_aspect("equal")
ax.set_title(r"Potential $\varphi$")
Text(0.5, 1.0, 'Potential $\\varphi$')
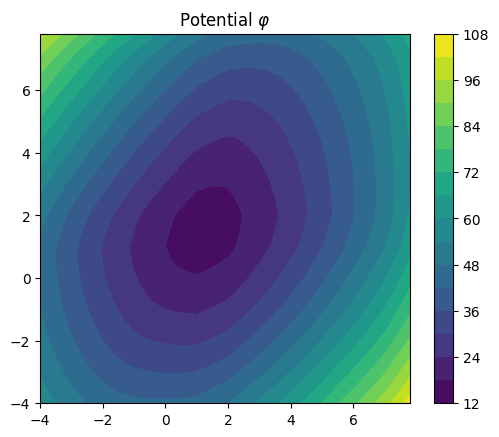
We leverage these ground-truth Monge maps and the ground-truth Benamou-Brenier velocity fields to define data to create a synthetic task that we will solve using flow matching.
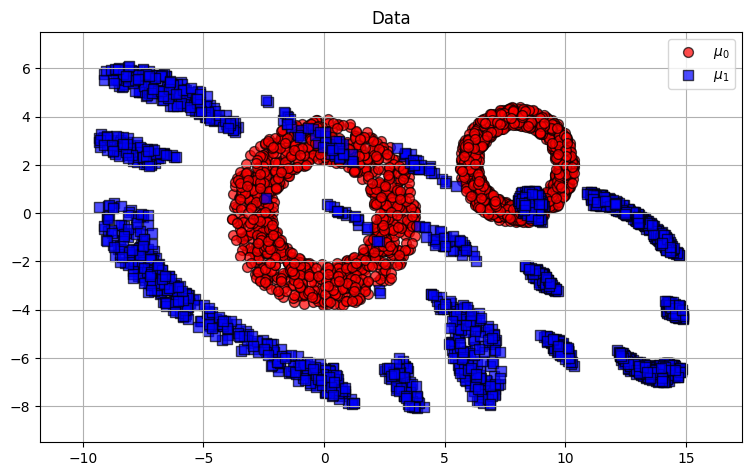
We do so by defining a source distribution, a union of two 2D toruses. We sample a few points from that distribution for plotting purposes.
full_plot = 2048
batch_plot = 256
hl_batch_plot = 32 # Smaller batch to highlight in plots.
def gen_torus_points(
key: jax.Array, fraction: float = 0.7, size: int = 1
) -> jax.Array:
# Generate point cloud near the unit circle.
points = jr.normal(key, (size, 2))
points /= jnp.linalg.norm(points, axis=-1, keepdims=True) + 1e-8
torus_norms = 2 * (1 - fraction) * jr.uniform(jr.key(1), (size,)) + fraction
points *= torus_norms[:, None]
return points
def gen_points(
rng: jax.Array,
batch_size: tuple[int, ...],
dtype: Optional[jnp.dtype] = None,
) -> jax.Array:
batch_size, *_ = batch_size
x = 3 * jnp.array(gen_torus_points(rng, size=batch_size // 2), dtype=dtype)
y = 2 * jnp.array(
gen_torus_points(rng, size=batch_size // 2, fraction=0.8), dtype=dtype
) + jnp.array((8, 2))
return jnp.concatenate([x, y])
rng1, rng2, rng3 = jr.split(jr.key(0), 3)
points = gen_points(rng1, batch_size=(full_plot,))
target_points = transport_fn(points)
points_sub = jr.choice(rng2, points, (batch_plot,), axis=0)
target_points_sub = transport_fn(points_sub)
hl_points = gen_points(rng3, batch_size=(hl_batch_plot,))
Data and Monge Solution#
We plot source points and the push-forward measure obtained by applying \(\nabla\varphi\) to these source points.
_ = plot.transport_animation(
n_frames=1,
static_src_points=points,
static_tgt_points=target_points,
title="Data",
)
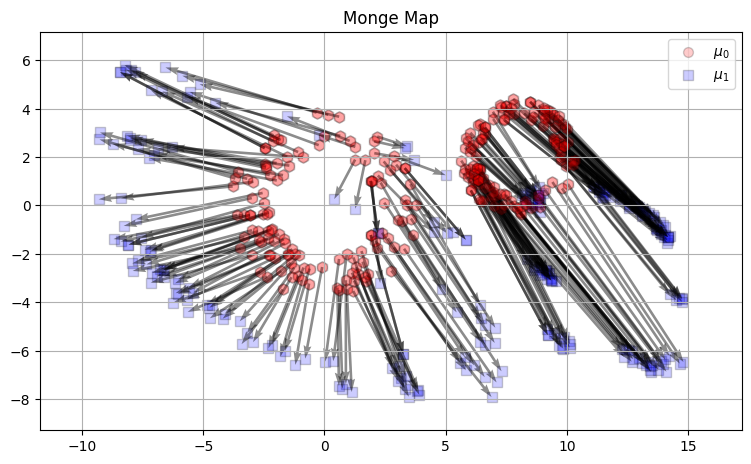
We show more explicitly the Monge map linking each source point to its target point, on a subset of points.
_ = plot.transport_animation(
n_frames=1,
static_src_points=points_sub,
static_tgt_points=target_points_sub,
velocity_field=velocity_brenier,
title="Monge Map",
)
McCann Interpolation#
This Monge map can be presented in a dynamic view, by plotting all barycenters linking source points to target points, \(x_t=(1-t)x + t \nabla\varphi(x)\), to form the so-called McCann interpolation [McCann, 1997].
to_video(
plot.transport_animation(
n_frames=11,
static_src_points=points_sub,
static_tgt_points=target_points_sub,
velocity_field=velocity_brenier,
title="McCann Interpolation",
)
)
Independent Interpolant#
The McCann interpolation (which requires the knowledge of the optimal transport map) can be compared with the independent interpolant [Albergo et al., n.d.], which is far easier to compute since it involve sampling independently a point from the source, then the target, and then linking them.
for plot_ifm_arrows, title in zip(
[False, True],
["Flow-Matching Interpolant", "Flow-Matching Interpolant + Velocities"],
):
to_video(
plot.transport_animation(
n_frames=11,
static_src_points=points_sub,
static_tgt_points=target_points_sub,
num_ifm_interpolants=256 if plot_ifm_arrows else "all",
plot_ifm_arrows=plot_ifm_arrows,
title=title,
)
)
Benamou-Brenier Solution#
Since this is a synthetic example, we can show what the Benamou-Brenier solution looks like, by displaying the time and space varying vector field \(\Delta t \times v_t(\cdot)\). Here \(\Delta t\) is the inverse of (n_frames - 1).
to_video(
plot.transport_animation(
n_frames=11,
n_grid=21,
static_src_points=points,
static_tgt_points=target_points,
velocity_field=velocity_brenier,
dynamic_src_points=jnp.empty([0, 2]),
title="Benamou-Brenier Velocity",
)
)
And illustrate that integration more carefully on one subset of highlighted points.
to_video(
plot.transport_animation(
n_frames=11,
n_grid=21,
static_src_points=points,
static_tgt_points=target_points,
velocity_field=velocity_brenier,
dynamic_src_points=hl_points,
title="Benamou-Brenier Integration",
)
)
Flow Matching#
Coupling Approaches#
Independent Coupling#
We first instantiate a data sampler that leverages the knowledge of the ground-truth transport map, but returns unpaired data.
def unpaired_dl(
rng: jax.Array,
batch_size: int,
potential: Callable[[jnp.ndarray], jnp.ndarray],
) -> Iterable[tuple[jnp.ndarray, jnp.ndarray]]:
while True:
rng, rng_x0, rng_x1 = jr.split(rng, 3)
x0 = gen_points(rng_x0, (batch_size,))
x1 = jax.vmap(jax.grad(potential))(gen_points(rng_x1, (batch_size,)))
yield x0, x1
batch_size = 256
dl_ind = unpaired_dl(jr.key(23), batch_size=batch_size, potential=phi)
Batch-OT Coupling#
We now build an OT-FM sampler that resolves pairs provided independently, using an OT solver (here the Sinkhorn algorithm) using the LinearOTDataloader.
dl_ot = ot_dataloader.LinearOTDataloader(
rng=jr.key(0),
dataset=dl_ind,
epsilon=0.1,
relative_epsilon="std",
)
Semidiscrete Coupling#
Finally, we instantiate the semidiscrete coupling approach by solving the problem with a SemidiscreteSolver.
Unlike the two methods above, where the data samplers draw from a continuous density, this assumes that the target dataset is finite.
# Semidiscrete pairs sampler, finite target sampled once
size_target = 2048
target_points = transport_fn(gen_points(jr.key(64), (size_target,)))
# Instantiate the SD geometry object
pc = sdpc.SemidiscretePointCloud(
sampler=gen_points,
y=target_points,
epsilon=0.0,
cost_fn=costs.NegDotProduct(),
)
sdpb = sdlp.SemidiscreteLinearProblem(pc)
num_iterations = 10_000
schedule = optax.linear_schedule(
init_value=10,
transition_begin=num_iterations // 4,
transition_steps=num_iterations // 2,
end_value=0.05,
)
error_eval_every = 500
pbar = trange(num_iterations, desc="SD Estimation")
def print_callback(state: semidiscrete.SemidiscreteState) -> None:
it = state.it.item()
if it > 0 and it % error_eval_every == 0:
loss = state.errors[it // error_eval_every - 1].item()
pbar.set_postfix(χ2=f"{loss:.4f}", 𝜀=f"{state.epsilon:.3f}")
pbar.update(error_eval_every)
solver = semidiscrete.SemidiscreteSolver(
num_iterations=num_iterations,
batch_size=512,
optimizer=optax.sgd(learning_rate=schedule),
error_eval_every=error_eval_every,
callback=print_callback,
epsilon_scheduler=lambda it, te: te + 0.1 * jax.nn.relu(1000 - it) / 1000,
)
sd_out = jax.jit(solver)(rng=jr.key(2), prob=sdpb)
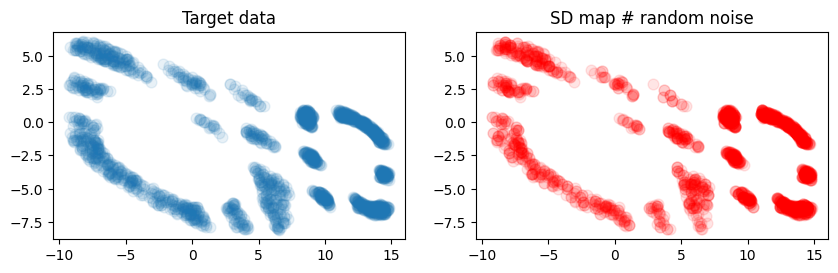
Once the semidiscrete problem has been solved, we can visually check whether the estimation is satisfactory. We simply evaluate a batch of noise, and plot where it has been mapped using the SemidiscreteDataloader. Ideally, that distribution of points should roughly match that which was used initially.
dl_sd_plot = sd_out.to_dataloader(jr.key(0), batch_size=size_target)
p, e_p = next(iter(dl_sd_plot))
fig, (ax0, ax1) = plt.subplots(1, 2, figsize=(10, 6))
ax0.scatter(pc.y[:, 0], pc.y[:, 1], s=60, alpha=0.1)
ax0.set_aspect("equal")
ax0.set_title("Target data")
ax1.scatter(e_p[:, 0], e_p[:, 1], color="r", s=60, alpha=0.1)
ax1.set_aspect("equal")
ax1.set_title("SD map # random noise")
# Dataloader with the correct batch_size to be used for training
dl_sd = sd_out.to_dataloader(jr.key(0), batch_size=batch_size)
Training of Velocity Fields#
We propose a simple training loop, that uses a dataloader to sample source/target pairs, and simply interpolates between them to form random points, barycenters, and directions the velocity field can be regressed on.
def train_loop(
rng: jax.Array,
dl: Iterable[tuple[jax.Array, jax.Array]],
name: str = "",
num_iters: int = 20_000,
log_every: int = 100,
) -> mlp.MLP:
model = mlp.MLP(dim=2, rngs=nnx.Rngs(1), hidden_dims=[64, 64])
optimizer = optax.adam(1e-3)
optimizer = nnx.Optimizer(model, optimizer, wrt=nnx.Param)
fm_step = nnx.jit(fm.flow_matching_step)
step_rngs = nnx.Rngs(0)
model.train()
dl_iter = iter(dl)
pbar = trange(num_iters, desc=f"{name} training")
for i in range(num_iters):
rng, rng_batch = jr.split(rng)
x0, x1 = next(dl_iter)
batch = fm.interpolate_samples(rng_batch, x0, x1)
metrics = fm_step(model, optimizer, batch, rngs=step_rngs)
if i % log_every == 0:
pbar.set_postfix(loss=f"{float(metrics['loss']):.4f}")
pbar.update(log_every)
return model
We train three different models, one for each approach: independent coupling IFM, batch-OT coupling OTFM and semidiscrete coupling SDFM. Note that the losses themselves cannot be compared across approaches, as the dataloaders that supply points to compute the regression loss are different. Obviously, OTFM is slower than IFM. Note that dataloader requires for both IFM and OTFM to evaluate ground-truth transported points, but not for SDFM which only uses a target set of size_target points.
models = {}
dls = {"IFM": dl_ind, "OTFM": dl_ot, "SDFM": dl_sd}
for meth_name, dl in dls.items():
model = train_loop(jr.key(0), dl=dl, name=meth_name)
model.eval()
models[meth_name] = nnx.jit(model)
We can see that there are clear differences between the three learned vector fields. IFM struggles to cover target modes and its velocity field wiggles more sharply across space. OTFM manages to recover an acceptable solution. It is likely that increasing the batch size would improve its performance further, for an additional compute cost. SDFM performs fairly well and results in a better conditioned velocity field overall.
for meth_name, model in models.items():
to_video(
plot.transport_animation(
n_frames=11,
title=meth_name,
n_grid=21,
static_src_points=points,
static_tgt_points=target_points,
dynamic_src_points=hl_points,
velocity_field=model,
)
)